在计算机视觉领域,目前主流的图像分类方法仍然是基于完备标注数据的有监督学习,然而,在实际场景中,完全而精确的图像标签往往难以获得。 例如,由于知识水平的差异不同的人可能对同一类图像有不同理解,从而给出不一致的标签。 此外,为了降低标注成本,可以利用预训练模型对采集的大规模数据进行自动标注,但往往会得到大量不准确的标签,仅仅其中的一小部分数据可以得到人工验证。然而,传统的有监督学习方法很难处理这类带有噪声标签的数据。 现有的弱监督图像分类方法通常对于噪声标签类型有特定的假设,如单标签噪声或者多标签噪声。 单标签噪声假设的分类方法,可以在训练过程中对于相似的图像进行聚类,而多标签噪声假设的分类方法,可以使用标签与标签之间的联系来增加算法的鲁棒性。 尽管这些方法有助于提升模型的性能,但是在一定程度上限制了模型的泛化能力。 为此,在这个工作中,我们关注于提升模型的泛化能力,期待模型可以同时应用于单标签数据和多标签数据。我们观察到尽管现有的方法使用不同的假设辅助分类器学习,核心思想依然在于区分大量噪声标签中的可信与不可信的信息。 如图1所示,一些使用标签与标签或者图像与标签之间关联的方法,会利用这些关系的正相关或者负相关强度来决定标签中的可用信息。 因此,我们提出了一种弱监督图像分类的方法,结合使用大量噪声标注数据和少量干净标注数据,通过两个子网络分别学习噪声标签中的可信与不可信的部分,减少了不可信的信息对模型的影响。 我们的方法可以同时应用于单标签和多标签数据,并且不依赖于成对的干净-噪声标注数据。 我们在两个多标签数据集(OpenImage和MS COCO2014)和一个单标签数据集(Clothing1M)评估了该方法。 实验结果表明,该方法优于现有的最好方法,并在单标签和多标签噪声假设的场景下有很好的泛化能力。 2.方法 图表 2 方法网络结构示意图 2.1问题定义 我们的目标是结合利用大量的噪声标注数据 D_n 和少量的干净标注数据 D_c 得到一个鲁棒的图像分类模型。 在现实场景中,我们可以假设噪声标注数据的数量 N_n 远大于干净标注数据的数量 N_c。 如图所示,我们以多任务学习的方式进行弱监督图像分类,同时训练两个分类器g和h分别拟合干净集合中的干净标签和噪声集合中的噪声标签。 主干网络CNN(Backbone CNN)用于学习共享特征。净化网络(clean net)用于学习从特征空间到干净标签空间的映射,残差网络(residual net)用于学习从特征空间到标签残差(干净标签和噪声标签之间)的映射。 分类器g为最终的目标分类器,用于学习映射F_c, 则分类器g可表示为: 分类器h为辅助分类器,用于学习映射 F_r, 则分类器h可表示为: 两个分类器同时使用了交叉熵损失,表示为: 则总体目标函数为: 2.2 用于噪声正则化的残差网络 分类器h可以被看作是g的噪声正则项的原因是,其工作方式与其他正则项的工作方式类似,都是用于缓解网络的过拟合问题。 所提方法中的残差网络可以建模大量噪声标注数据中的不可信部分,从而反过来使得分类器g可以利用数据中的可信部分,进而提高分类器的鲁棒性。 3.实验结果 3.1数据集 为了测试所提出方法的有效性,我们在三个数据集上进行了实验,包括两个多标签数据集(MS COCO2014 和 OpenImage) 和一个单标签数据集(Clothing1M)。 3.2 评测指标 对于多标签数据,我们选取了平均准确率(mAP) 以及总体准确率(AP_all)。其中平均准确率是针对所有类别的准确率的平均值,而总体准确率是将所有类别看作同一类的准确率结果。 对于单标签数据,我们选取了top-1准确率作为评测指标。 3.3实验结果 在MSCOCO和OpenImage数据集上,我们分别选取了5%-20%比例的干净标签和全部的人工确认标签作为干净数据集合。 可以看出,与基准方法比较,即使干净数据只有5%的比例,我们的方法依然能有较好的性能提升。 在Clothing1M上,我们的结果与其他SOTA方法相差无几。然而,CleanNet 和 Forward方法严格基于单标签假设,而我们的模型泛化能力更佳。 为了显示残差网络的影响,我们比较了不同的训练方式。可以看出,加入残差网络,以协同的方式训练分类器g和h,在OpenImage 和Clothing1M上 可以分别提升1.4%(mAP) 和 4.8% (top-1)。 4.结论 当实际应用中大规模干净数据集不可得的时候,利用大规模噪声标注数据的弱监督图像分类变得很有价值。 但是由于噪声数据中的语义信息难以准确获得,导致问题十分具有挑战性。我们通过提出一种新的可端到端训练的方法来解决这个问题。 该方法由一个净化网络(clean net) 和一个残差网络(residual net) 组成,残差网络通过学习噪声标签和干净标签之间的残差以缓解净化网络对于干净标签过拟合的风险。 多标签和单标签数据集的实验结果表明模型在提升准确率的同时拥有更好的泛化能力。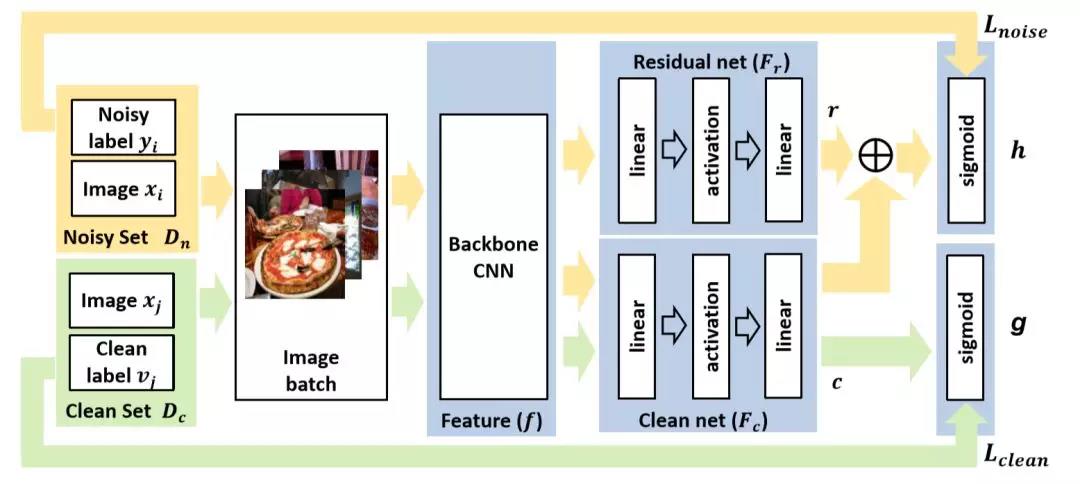
上一篇:力天创见排队客流统计
